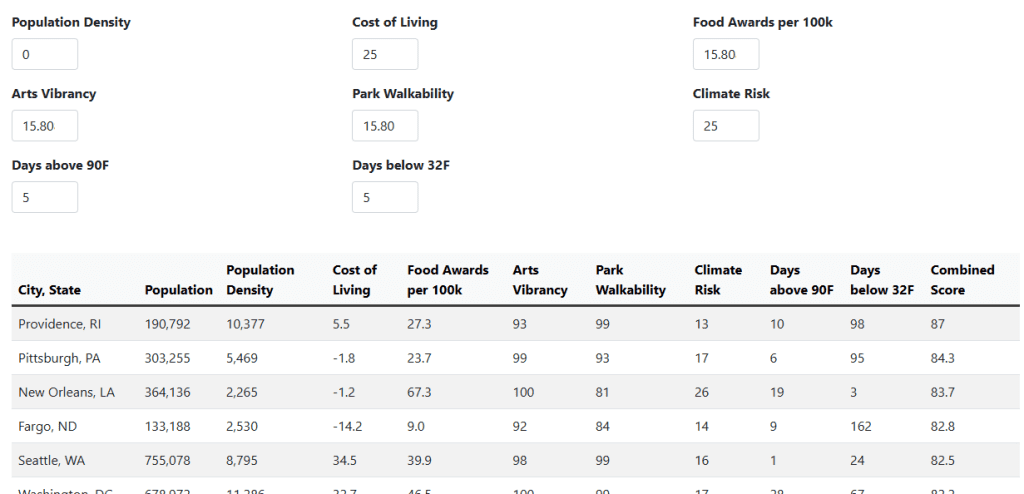
Where to Move To
Tell the tool what factors are important to you, and it shows you the best cities based on those factors. You can adjust how much each factor matters by changing the percentages. For example, if having lots of parks nearby is important to you, you can give that a higher percentage. If you don’t care about population density, you can set that one to zero.
The URL changes as you change your numbers so if you want to share, just copy the URL!
Data Sources
Here’s a quick rundown of where the data comes from:
- Population Data: All U.S. cities with over 100,000 people.
Cost of Living: Compiled from multiple sources: – Economic Policy Institute – Payscale – AdvisorSmith – Numbeo – BestPlaces, in order of preference.
Food Awards: James Beard awards excellent restaurants and chefs.
Arts Vibrancy: Data sourced from SMU DataArts’ Arts Vibrancy Map, based on counties. If a city lies in multiple counties, the score is proportionally assigned.
Park Walkability: Percentage of residents within a 10-minute walk to a park, sourced from the Trust for Public Land (TPL). Initially tried Walk Score, but it overemphasized downtown areas.
Climate Risk: Based on the ProPublica article’s table. The score is calculated by summing six different scores for each county, then converting from county to city proportions as mentioned above.
Days above 90F & Days Below 32F: Counted the number of days above/below for the last 10 years and then divided giving an average of the number of days.
Wordle: Best Starting Word
(tldr; Best 5 words are Nares, Lares, Kaies, Tares, and Canes in that order.)
Letter Frequency
I grabbed a table of letter frequency (‘General Text’) from Wikipedia, but quickly realized that the letter frequencies for five letter words might be completely different than for general text. So I ran my own analysis on five letter words (‘5 Letter Words’).
The most common letter in five letter words is “S”, but “E” is still very popular!
For the first word you wouldn’t want to have any double (or triple letter words, lookin at you Ninny, Tatty, etc…) because that would reduce the total amount of information you’d get. Re-running the analysis on the list of five letter words without double and triple letter words reveals a slightly different frequency of letters (‘No Dupes’).
From the No Dupes list the fiver letters with the highest frequency are S, E, A, R, & O. Since I’m no good at rearranging letters in my head the Internet Anagram Server reveals one word “Arose”. Which seems to track pretty well with some other people.
“Arose” does an excellent job of meeting the letter frequencies, which gives it a high probability of returning green or yellow letters.
| General Text | 5 Letter Words | No Dupes | |
|---|---|---|---|
| A | 8.20% | 9.24% | 8.84% |
| B | 1.50% | 2.51% | 2.44% |
| C | 2.80% | 3.13% | 3.42% |
| D | 4.30% | 3.78% | 3.95% |
| E | 13.00% | 10.27% | 9.31% |
| F | 2.20% | 1.72% | 1.56% |
| G | 2.00% | 2.53% | 2.58% |
| H | 6.10% | 2.71% | 2.96% |
| I | 7.00% | 5.80% | 6.31% |
| J | 0.15% | 0.45% | 0.46% |
| K | 0.77% | 2.32% | 2.43% |
| L | 4.00% | 5.20% | 5.20% |
| M | 2.50% | 3.05% | 3.06% |
| N | 6.70% | 4.55% | 4.91% |
| O | 7.50% | 6.84% | 6.51% |
| P | 1.90% | 3.11% | 3.11% |
| Q | 0.10% | 0.17% | 0.22% |
| R | 6.00% | 6.41% | 6.76% |
| S | 6.30% | 10.28% | 9.44% |
| T | 9.10% | 5.08% | 5.11% |
| U | 2.80% | 3.87% | 4.32% |
| V | 0.98% | 1.07% | 1.11% |
| W | 2.40% | 1.60% | 1.77% |
| X | 0.15% | 0.44% | 0.52% |
| Y | 2.00% | 3.20% | 3.12% |
| Z | 0.07% | 0.67% | 0.57% |
| Positional Frequency | ||||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| A | 4.75% | 17.44% | 10.45% | 7.95% | 3.6% | A |
| B | 7.37% | 0.5% | 2.34% | 1.49% | 0.5% | B |
| C | 7.8% | 1.45% | 3.32% | 3.36% | 1.15% | C |
| D | 5.46% | 0.58% | 2.61% | 3.82% | 7.27% | D |
| E | 1.67% | 10.11% | 5.09% | 18.29% | 11.39% | E |
| F | 5.3% | 0.13% | 0.83% | 1.11% | 0.42% | F |
| G | 5.35% | 0.41% | 2.58% | 3.14% | 1.43% | G |
| H | 3.8% | 4.7% | 0.94% | 2.13% | 3.26% | H |
| I | 1.2% | 10.98% | 9.58% | 7.93% | 1.87% | I |
| J | 1.56% | 0.07% | 0.38% | 0.28% | 0.01% | J |
| K | 2.67% | 0.5% | 2.27% | 4.43% | 2.3% | K |
| L | 4.78% | 5.97% | 6.37% | 5.47% | 3.41% | L |
| M | 5.58% | 1.33% | 3.89% | 2.96% | 1.54% | M |
| N | 2.25% | 2.69% | 8.05% | 6.81% | 4.73% | N |
| O | 2.24% | 16.5% | 6.44% | 4.78% | 2.58% | O |
| P | 7.01% | 1.81% | 2.58% | 2.96% | 1.21% | P |
| Q | 0.78% | 0.14% | 0.13% | 0.02% | 0.02% | Q |
| R | 4.67% | 8.11% | 10.24% | 5.42% | 5.35% | R |
| S | 10.05% | 0.64% | 2.75% | 3.51% | 30.25% | S |
| T | 6.08% | 1.66% | 4.64% | 6.61% | 6.57% | T |
| U | 1.77% | 9.59% | 6.19% | 3.53% | 0.52% | U |
| V | 2.09% | 0.34% | 1.98% | 1.12% | 0.04% | V |
| W | 3.51% | 1.21% | 2.4% | 1.17% | 0.55% | W |
| X | 0.11% | 0.47% | 1.21% | 0.12% | 0.67% | X |
| Y | 1.44% | 2.4% | 1.8% | 0.87% | 9.11% | Y |
| Z | 0.75% | 0.25% | 0.91% | 0.73% | 0.23% | Z |
If we want to maximize the number of green letters we could look at the letter frequency for each position in a 5 letter word.
“Arose” doesn’t have the best positional frequency. Unsurprisingly, the table reveals lots of words end in “ES”.
We can score a given word using the positional frequency table. Take “Fumes” for example. We’ll take each positional percentage (i.e. F’s percentage in column 1 is 5.3%), add them together, and divide by 5.
| F | U | M | E | S | Total | Total/5 |
|---|---|---|---|---|---|---|
| 5.3% | 9.59% | 3.89% | 18.29% | 30.25% | 67.32 | 13.46% |
This gives us a score of how well each word’s letters match the positional frequency.
Here are the top 10 words generated with this method:
- Cares – 16.80%
- Bares – 16.71%
- Pares – 16.64%
- Cores – 16.61%
- Bores – 16.53%
- Tares – 16.46%
- Pores – 16.46%
- Canes – 16.36%
- Mares – 16.36%
- Dares – 16.33%
Looks like other people score “Cares” pretty well too. Scrolling way down the rankings, “Arose” is 5891th.
Elimination of Other Words
I had one other thought about word ranking. If you guessed a word and none of the letters matched (all gray) then the list of words that remain can’t contain those letters. Words with more common letters will eliminate more words, whereas words with less common letters will eliminate fewer words.
If every letter in “Cares” was gray that would reduce the total number of possible words by 93.09%.
I looked at how many words would be eliminated if each word in the list was all gray. Which, by the way is 168,272,784 comparisons.
Some pretty uncommon words float to the top 10 of this list, but they all look like high quality starting words. Also “Arose” rose close to the top!
- Toeas – 95.72%
- Stoae – 95.72%
- Aloes – 95.68%
- Aeons – 95.64%
- Arose – 95.55%
- Aeros – 95.55%
- Soare – 95.55%
- Aesir – 95.17%
- Reais – 95.17%
- Serai – 95.17%
Best Rated Words
Now that we’ve got two solid ranking systems, let’s combine them and see what floats to the top. For this I’m taking a word’s position in each list and adding them together and sorting. For example, “Caves” is in position 81 of the positional frequency list and in position 853 of the elimination list giving it a score of 934. After adding all the words scores together and sorting the list we get to the final combined scores list.
- Nares
- Lares
- Kaies
- Tares
- Canes
- Cares
- Lanes
- Rales
- Rates
- Tales
- Cates
- Hares
- Lores
- Nates
- Taces
- Manes
- Rones
- Mares
- Races
- Yates
- Panes
- Pares
- Gares
- Aures
- Roles
- Yales
- Dates
- Roues
- Aunes
- Dares
Worst Rated Words
Since we’ve built out this system, we might as well look at the worst rated starting words.
- Oxbow
- Xylyl
- Immix
- Infix
- Fluff
- Ungum
- Undug
- Whizz
- Urubu
- Uhuru
- Cwtch
- Ictic
- Chuff
- Whiff
- Jugum
- Kudzu
- Whump
- Phpht
- Zhomo
- Gyppo
- Ghyll
Reverse Engineering Oatly: Part 3
This is the third part of the reverse engineering Oatly Project (Part 1 & Part 2). I’ve done more experimentation and simplified the recipe. Make sure to read the first two parts for more context!
I bought a Brix Refractometer to measure the amount of sugar over time, and found that I could do a single cooking temperature for one hour and get similar sugar levels to the previous recipe.
Also, I made corn milk with this recipe. It wasn’t great. Maybe some more experimentation would help. Weirdly, it smelled exactly like the oat milk.
Best/Easiest Oat Milk Recipe So Far
| Water | 680 gr |
| Rolled Oats | 80 gr |
| Malted Barley | 8 gr |
| Canola Oil | 22 gr |
| Salt | 1 gr |
- Pre-heat the immersion circulator bath to 150F (65C).*
- Toast oats in the oven at 250F (121C) for 8 minutes.**
- Add oats and malted barley to water and blend until fine; add mixture to a 1 quart (~1 liter) Mason jar (make sure the lid is tight!).
- Put the jar in the water bath for 1 hour. Shake the jar after 30 minutes.
- Filter the oat mixture through a nut milk bag.
- Add the oil and salt to the filtered oat milk and blend.
- Chill & drink!
*Temperature is critical here; this recipe will be hard to reproduce without an immersion circulator. If the temperature goes much beyond 150F (65C) the enzymes will denature and stop converting the starches in the oats to sugars.
**The toasting is different for different oats. Preheat your oven to 250F (121C), put some oats on a cookie sheet, and set a timer for 4 minutes. At 4 minutes, pull a few oats out to taste. The oats done are when they have a hint of roastiness with no bitter/burnt/off flavor. If they aren’t done, give it another 4 minutes. Different brands of oats we’ve tested have required between 4 and 12 minutes. Instant oats seem to need longer, while fancier non-instant oats need shorter times.

UV Light Meter
Sarah & I have been experimenting with Cyanotypes lately. We picked up a Photographer’s Formulary Cyanotype Kit. We also got a pretty large contact printing frame. I had built a really basic exposure unit a while back with some UV LED tape.
We figured out with test strips that to get a rich dark blue we needed an exposure time of about 75 minutes. 75 minutes is kind of a long time though, so we wanted to try using the sun, but of course, the sun’s output is pretty variable — clouds might block the sun for a while and summer vs. winter has pretty significant output changes.
I had the idea that you could use a sensor to measure the UV light and count up how much UV had hit the cyanotype and have consistent exposures no matter how much the sun’s output changes.
I picked up a UV light sensor, a little two row display, and connected them up over I2C to a Raspberry Pi I had sitting around.

A bit of Python and I had a prototype. Briefly, the sensor takes one reading per second, adds that value to a running tally, and sees how many more seconds it will take to hit the desired exposure.
Interestingly, the hardest part here was figuring out how to time one second. If you have a basic loop that works like this:
Loop:
Get start time
Measure Light Intensity
Sleep until it’s one second later than the start time
You’ll discover there’s overhead on making the loop happen, getting the start time, and even on the sleep. So my loops were actually taking longer than a second. (It seems like the right way to do this is with Timer Interrupts? In the the second version of this prototype, I’m going to look into that.)
So, to get my seconds closer to one second, every time the meter is used, it saves the average time a loop took, and reduces the loop time proportionally so the actual loop time is closer to 1 second. Based on some testing I think the timing is now accurate to 0.0001± second.
In any case, the light meter seems to work pretty well, though if the sun is at a particularly low angle, the timing seems to be off. I need to experiment more.
Human in Photo?
I shot a timelapse of Sarah binding her thesis. I used the timelapse system described in a previous post. I was left with about 12,000 frames, but only some of them had Sarah actually doing work in them.
I needed to build a timelapse of Sarah working. I tried several libraries that look for human shapes in photos, but they ended up being, inaccurate, slow, or overly complicated.
I had tested out Imagga for an unrelated tagging project a few years back, and it looks like at some point in the interim they added some face detection tools. With a basic account you get 1000 API calls per month, and after some testing it looked like Imagga would be fast and easy to use.
This passes an image to Imagga asking it to find a human, and then just counts the number of characters in the returned data. The data is pretty short if there’s no humans, and it’s longer if there is a human.
1/7